Agent Reach Gives AI Agents Live Eyes on Twitter, Reddit, and GitHub — No API Keys Required
The open-source CLI tool wraps platform scrapers and Jina Reader into a single agentic interface, letting Claude Code, Cursor, and friends read social signals and code repos without expensive API subscriptions.
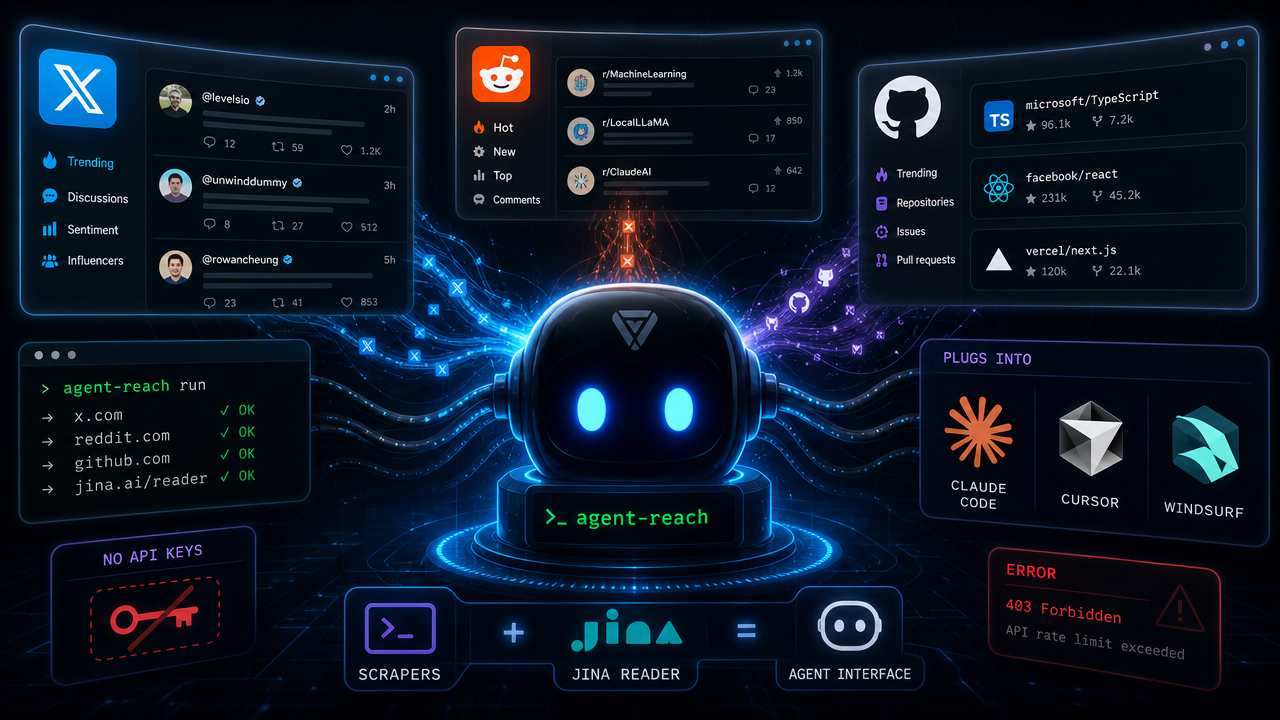
Most AI coding agents are brilliant at manipulating code but blind to the live internet. Ask one to summarize a Reddit thread about a bug you're chasing, fetch reactions to a library release on Twitter, or inspect a GitHub repo's open issues — and you'll get a 403, an empty response, or a hairball of raw HTML. Agent Reach, a Python CLI that hit 23.8k GitHub stars, is a direct fix for that gap.
What It Actually Does
Agent Reach wraps a collection of existing scraping and reader tools — yt-dlp, twitter-cli, rdt-cli, Jina Reader, and an MCP-connected Exa search integration — behind a single unified CLI. The project's pitch is explicit: zero API fees, open source, cookies stored only on your local machine.
The platform matrix breaks down into two tiers:
Works out of the box (no config)
- General web reading (via Jina Reader)
- YouTube subtitle extraction + search
- RSS/Atom feeds
- GitHub public repo reading and search
- Weibo hot topics, search, user timelines
- WeChat public account article search and full-text extraction
- V2EX hot posts and thread details
Unlocked after one-time cookie or credential setup
- Twitter/X: search, timeline browsing, posting
- Reddit: full post + comment reading via
rdt-cli(login required) - XiaoHongshu: read, search, post, comment
- LinkedIn: profile and company page details, job search
- Bilibili: works locally without proxy; server deployments need a ~$1/month proxy
For platforms that require cookies, the recommended flow is: log in via browser → export with the Cookie-Editor Chrome extension → hand the cookie blob to your agent. The tool stores credentials locally; nothing is uploaded.
The semantic web search integration uses Exa via MCP and is advertised as free with no API key needed.
How Agents Install and Use It
The install UX is deliberately agent-native. You don't run a shell command yourself — you paste a single instruction into whatever agent you're using:
Help me install Agent Reach: https://raw.githubusercontent.com/Panniantong/agent-reach/main/docs/install.md
The agent fetches the install doc, then handles the rest: pip install agent-reach, installs system dependencies (Node.js, gh CLI, mcporter, twitter-cli, rdt-cli), configures Exa search via MCP, and registers a SKILL.md so the agent knows what capabilities are available. The same pattern works for updates.
A --safe flag skips automatic system package installs and just tells you what's needed — useful if you're auditing what gets installed before letting it run.
Agents supported include Claude Code, OpenClaw, Cursor, and Windsurf. The only hard requirement is that the agent can execute shell commands. OpenClaw users need to explicitly set tools.profile to "coding" since its default messaging profile blocks shell execution.
There's also a built-in diagnostic:
agent-reach doctor
This reports which platform connectors are healthy, which are broken, and what to do about it — useful given that scraping tools routinely break as platforms update their defenses.
Why This Pattern Matters for Agentic Workflows
The real value here isn't any single integration; it's the aggregation model. Building one-off scrapers for each platform is tedious and fragile. Every platform has its own authentication quirks, rate limits, and HTML structures that change without notice. Agent Reach centralizes that maintenance burden: when a platform blocks a scraper, the project patches it upstream, and users just run the update command.
For developer use cases specifically, the GitHub integration (public repo reads, issue browsing, search) and Reddit support (community bug reports, ecosystem discussions) give agents access to signals that are genuinely useful during research and debugging. Pair that with live Twitter/X search for release reactions or security disclosures, and an agent gets a reasonable approximation of what a developer would actually look up manually.
The reliance on browser cookie export rather than official OAuth flows is a pragmatic workaround — it means no API billing, but also no guarantees against breakage if platforms change their cookie schemas or step up bot detection. The doctor command exists precisely because this is expected to happen.
With 23.8k stars and 249 commits logged, the project has enough traction to suggest its maintenance bet is worth watching. The architecture is transparent enough to audit before deployment.
Discussion 0
Join the discussion
Sign in with GitHub to comment and vote.
No comments yet
Be the first to weigh in.